




DAGOREPORT - SE C'È UN FILO DI CONTINUITÀ NELLA STORIA DELL’ITALIETTA, UN ELEMENTO CHE RIMBALZA DA…

MOGLI E "BOT" DEI PAESI TUOI - FASTWEB SI LANCIA NELLA CORSA ALL'INTELLIGENZA ARTIFICIALE ACQUISTANDO UN SUPERCOMPUTER PER LA REALIZZAZIONE DEL PRIMO SISTEMA DI IA NATIVO ITALIANO: UN SISTEMA DEL GENERE SAREBBE IN GRADO DI INTERPRETARE MEGLIO LA NOSTRA LINGUA, CON L'OBIETTIVO DI GARANTIRE UNA MIGLIORE TUTELA DELLA PRIVACY PER GLI UTENTI...
Estratto dell'articolo di Manuel Follis per "la Stampa"
[…] Fastweb […] entra nel vivo della partita legata all'intelligenza artificiale. Il gruppo che da pochi mesi è guidato da Walter Renna si candida alla realizzazione di un Super computer nazionale di IA con l'acquisto di un sistema costituito da 31 Nvidia Dgx H100. Il sistema sarà installato in uno dei suoi datacenter che la società possiede in Lombardia e con l'obiettivo, grazie al lavoro un team di esperti di Intelligenza Artificiale, di sviluppare il primo algoritmo (Large Language Model) nativo italiano.
Il data center Fastweb di ultima generazione nel quale sarà installato il dispositivo, interamente alimentato da energia rinnovabile, sarà operativo entro la prima metà del 2024 e sarà messo a disposizione di aziende, università, Pubbliche Amministrazioni per lo sviluppo di servizi ed applicazioni di intelligenza artificiale. […]
L'operazione era stata in qualche modo supportata dal sottosegretario per l'innovazione tecnologica e la transizione digitale Alessio Butti, che aveva invitato le aziende a sfruttare forme di partnerariato pubblico-privato per sviluppare una rete di supercomputer per l'IA. Per dare un'idea di che tipo di investimento e di tecnologia si tratta è utile un confronto con altre tecnologie già note e utilizzate. Tra i Large Language Model più noti c'è GPT-3 (il sistema che alimenta ChatGPT e che sarà sostituito da GPT-4) che ha 175 miliardi di parametri, MT-NLG di Nvidia e Microsoft arriva a 530 miliardi mentre il più grande in assoluto è WuDao 2.0 dell'Accademia di Pechino per l'intelligenza artificiale, con 1.750 miliardi di parametri.
Punti critici di queste operazioni sono la governance dei dati insieme alle questioni di privacy e di protezione dei dati. A questo si aggiungono temi etici, perché il reperimento di dati per poter addestrare il linguaggio espone al rischio di usare contenuti carichi di odio, discriminazione, ma anche informazioni errate e potenzialmente dannose. «Questo LLM nazionale - ha spiegato Fastweb nel suo comunicato - sarà in grado di funzionare da piattaforma per lo sviluppo di un ampio range di applicazioni di Intelligenza Artificiale Generativa, catturando sfumature della lingua italiana, della sua grammatica, del contesto e della specificità culturale nazionale».
[…]
DAGOREPORT - SE C'È UN FILO DI CONTINUITÀ NELLA STORIA DELL’ITALIETTA, UN ELEMENTO CHE RIMBALZA DA…
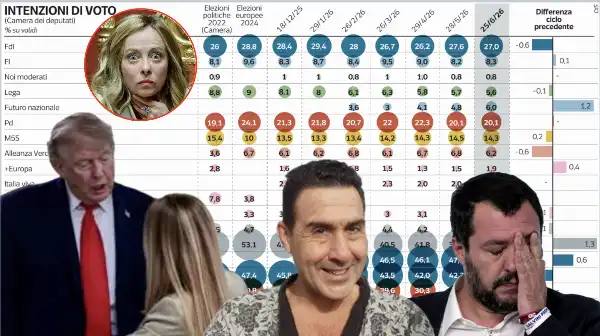
DAGOREPORT - DISGREGARE L’UNIONE EUROPEA, ALIMENTANDO FINANZIARIAMENTE LE FORZE SOVRANISTE EUROPEE,…

DAGOREPORT - CON L'ARMATA BRANCA-MELONI SOTTO SCHIAFFO DEL VANNACCISMO, IL CENTROSINISTRA RIESCE A…

DAGOREPORT – PERCHÉ MARIO ORFEO HA DETTO ADDIO A “REPUBBLICA”? DIETRO ALLE DIMISSIONI C’È UNA…

FLASH! - CHE SUCCEDE A "LA REPUBBLICA"? IERI SI E' DIMESSO L'INVIATO LIRIO ABBATE, OGGI MARIO ORFEO…

FLASH! - ALL'INDOMANI DEL VIOLENTO SCAZZO CON QUERELA TRA IL GOVERNATORE DELLA LIGURIA MARCO BUCCI,…